
LSA (Latent Semantic Analysis) — это метод анализа текстов, используемый для выявления смысловой связи между документами и запросами. Он является одним из самых популярных и эффективных алгоритмов для задачи поиска похожих документов.
Принцип работы LSA заключается в построении матрицы термы-документы, в которой строки соответствуют термам, а столбцы — документам. Затем применяется сингулярное разложение матрицы, позволяющее выделить наиболее информативные компоненты и устранить шумовые. Это позволяет получить понятийное пространство, где каждый документ представлен в виде вектора, а сходство между документами определяется по косинусной мере.
Преимущества LSA заключаются в его способности анализировать семантическую связь между документами, даже если они содержат разные слова или термины. Это делает алгоритм особенно полезным для поиска похожих документов в больших корпусах текстов или при работе с неструктурированными данными.
Принципы работы алгоритма LSA
Алгоритм LSA (Latent Semantic Analysis) основан на идее поиска скрытых семантических связей между документами. Он использует математические методы, чтобы выявить подобие основных тематических компонентов в коллекции документов.
Процесс работы алгоритма LSA состоит из следующих этапов:
- Степень важности слов: Вначале LSA вычисляет веса слов в каждом документе. Для этого создается матрица терминов на основе данных коллекции документов. Затем применяется метод TF-IDF (Term Frequency-Inverse Document Frequency), который оценивает важность слова в документе по его частоте встречаемости и появлению в других документах.
- Снижение размерности: После определения степени важности слов, LSA производит снижение размерности матрицы терминов для устранения шума и избыточности данных. Для этого используется SVD (Singular Value Decomposition) — метод линейной алгебры, который разлагает матрицу на произведение трех матриц: двух ортогональных и диагональной.
- Поиск схожих документов: После снижения размерности, LSA применяет метод косинусного сходства для сравнения документов и оценки их схожести. Косинусное сходство измеряет угол между векторами представления документов и определяет степень их близости.
Алгоритм LSA широко применяется в задачах информационного поиска, классификации текстов, а также для автоматической генерации тегов и резюме. Его основными преимуществами являются возможность обрабатывать большие объемы текста и выявлять скрытые семантические связи между документами без явного задания правил и критериев.
Итог
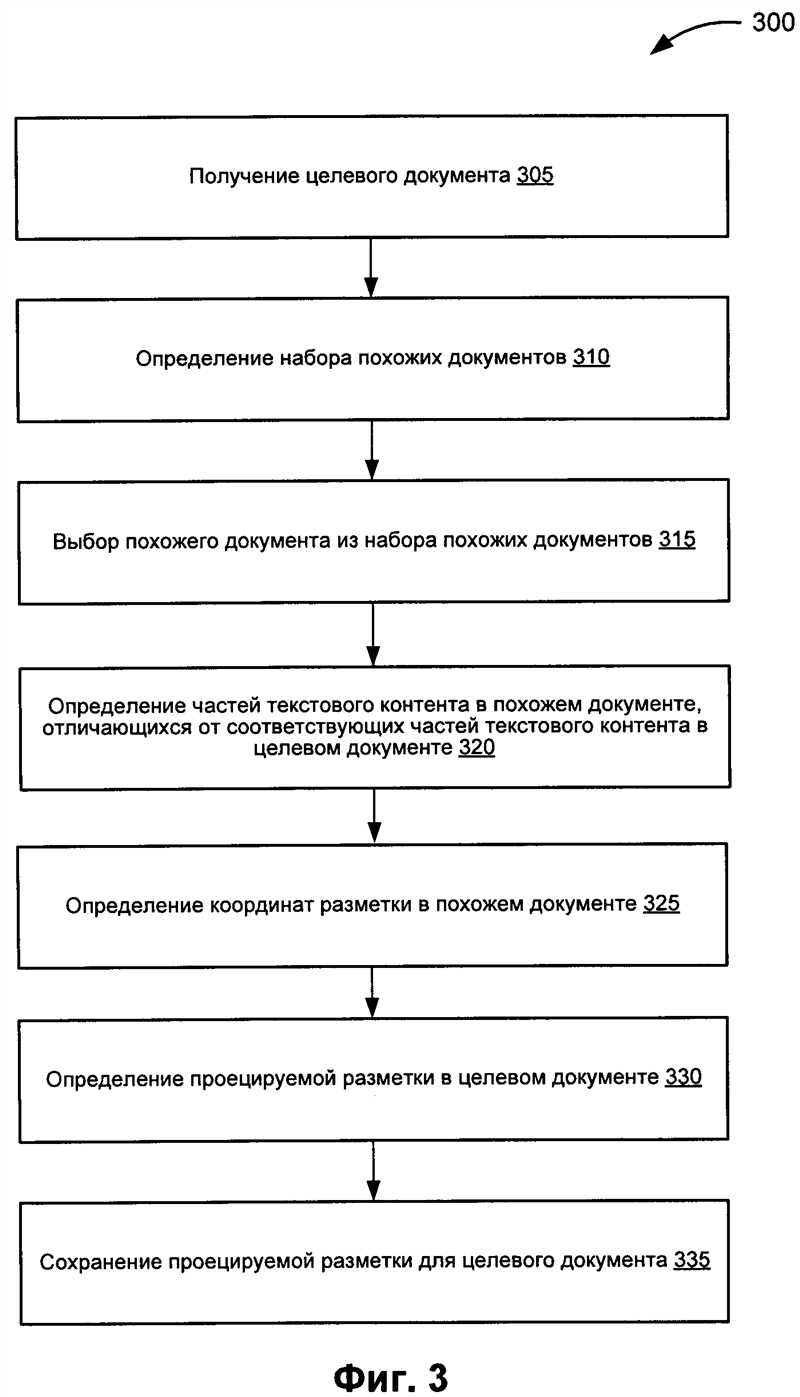
Применение алгоритма LSA для поиска похожих документов требует следующих шагов:
- Предобработка текстовых данных: удаление стоп-слов, лемматизация, векторизация текстов.
- Построение матрицы терминов-документов, основанной на частоте встречаемости слов в текстах.
- Применение сингулярного разложения матрицы для редукции размерности и выделения семантической информации.
- Вычисление сходства между документами на основе косинусного расстояния между векторами.
Алгоритм LSA демонстрирует высокую эффективность и точность при поиске похожих документов. Он позволяет учитывать не только точное совпадение слов, но и их семантическую близость. Применение LSA может значительно улучшить качество поисковой системы и рекомендательных алгоритмов.
Возможное дальнейшее развитие исследований в области LSA включает использование более сложных моделей, таких как LDA (Latent Dirichlet Allocation) и Word2Vec, для повышения точности и семантической нагрузки алгоритма. Также стоит учесть, что применение LSA может потребовать больших вычислительных ресурсов при работе с большими объемами данных.
Наши партнеры: